Training deep learning models is a bit like tuning a car, you've got a bunch of knobs to adjust, and finding the sweet spot takes patience and know-how.
The Learning Rate Saga
The learning rate is probably the most critical hyperparameter you'll deal with. Set it too high and your model overshoots the optimal solution; too low and you'll be waiting forever for it to converge [1]. The animation below shows this in action, watch how a tiny learning rate barely moves along the loss surface, a reasonable one glides toward the minimum, and a large one just bounces right past it:
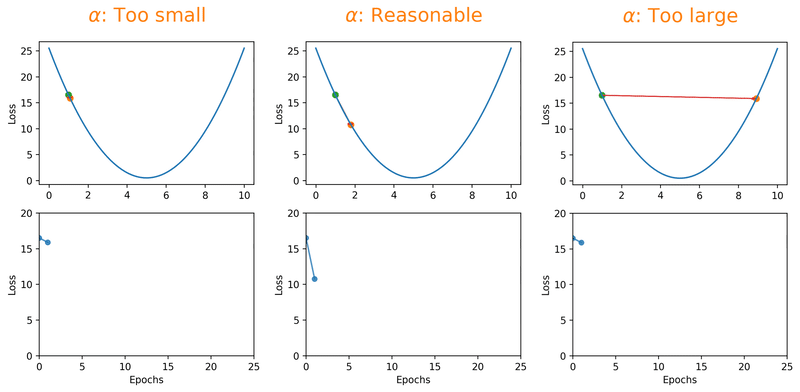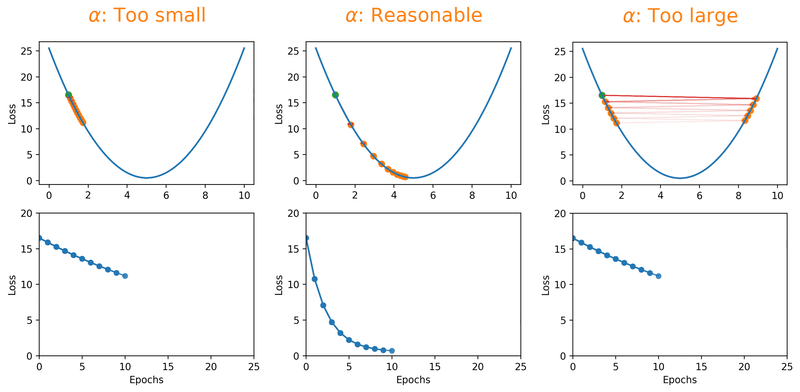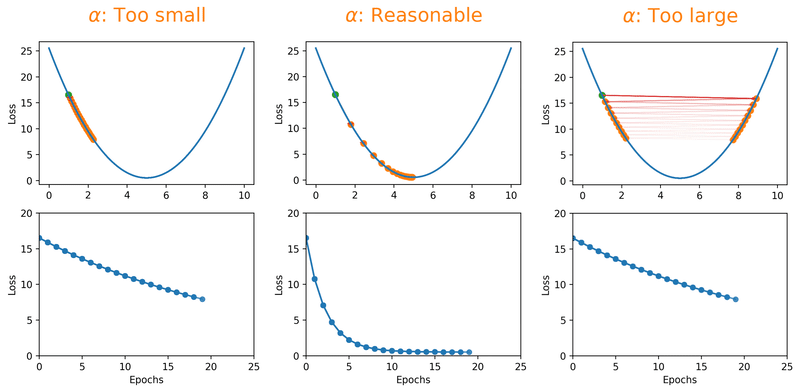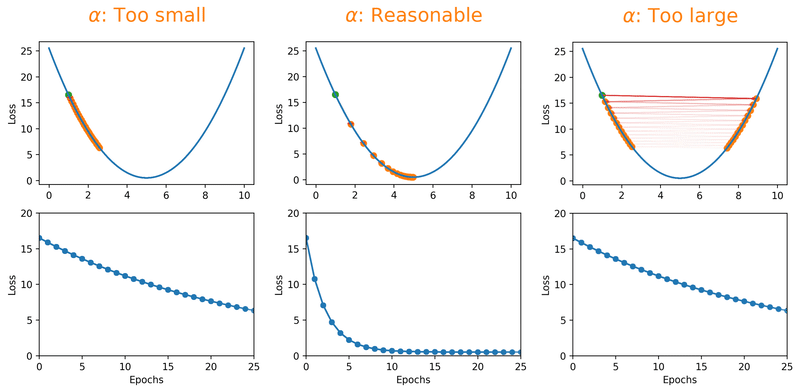
But here's the thing, even a "reasonable" constant learning rate can only get you so far. What if you could start bold and get more careful as you go? That's exactly what learning rate decay schedules do. By starting with a larger learning rate, you get the rarely discussed benefit of escaping local minima that overfit, and then as the rate decreases, you settle into a broader, better minimum:
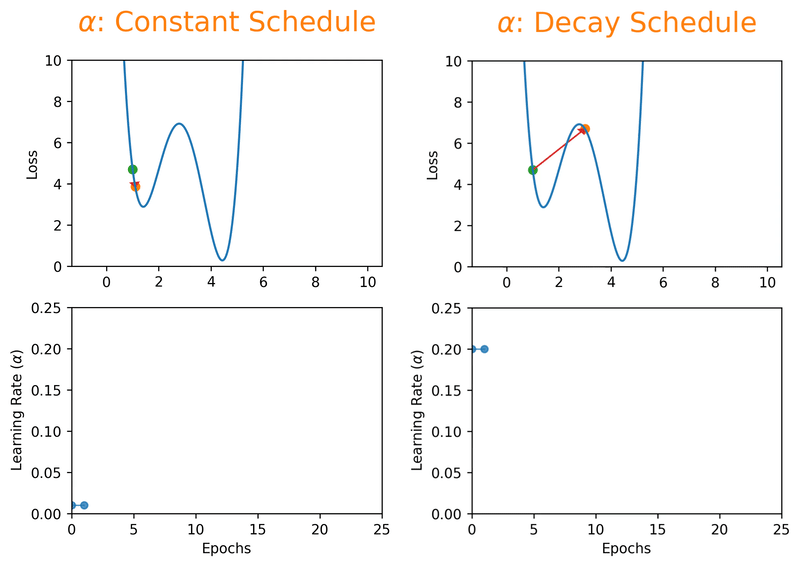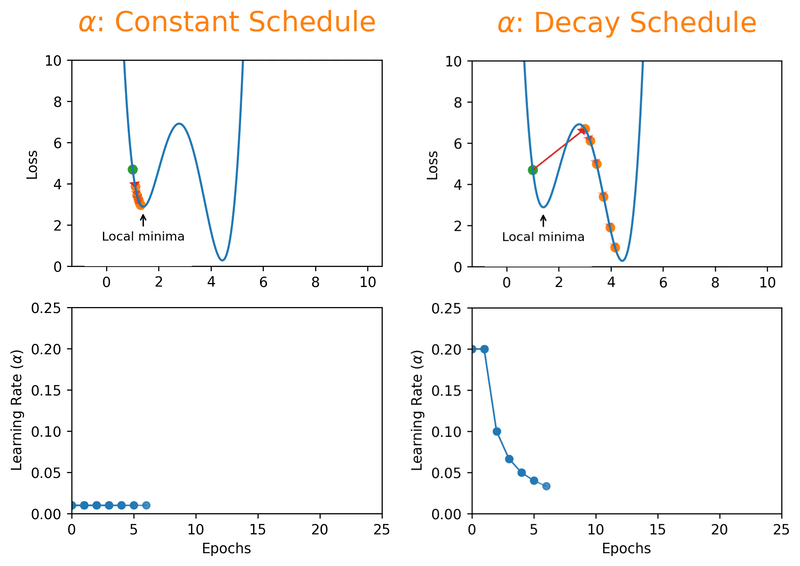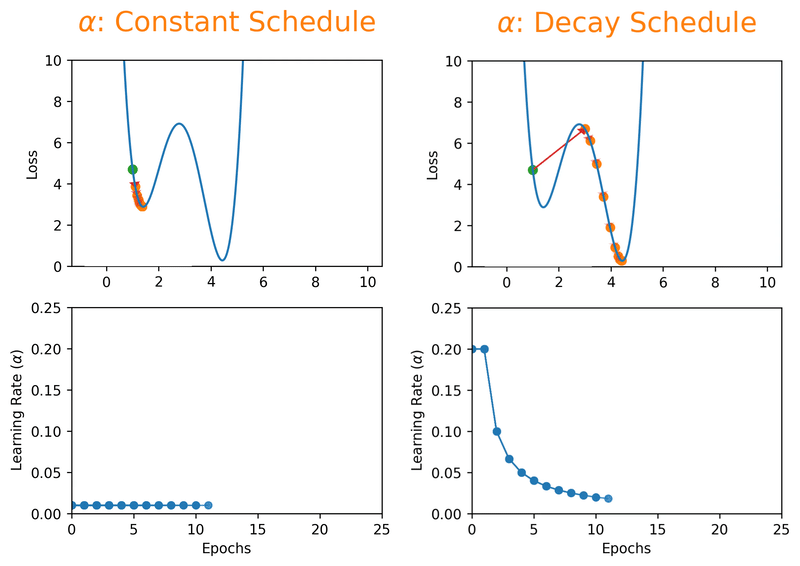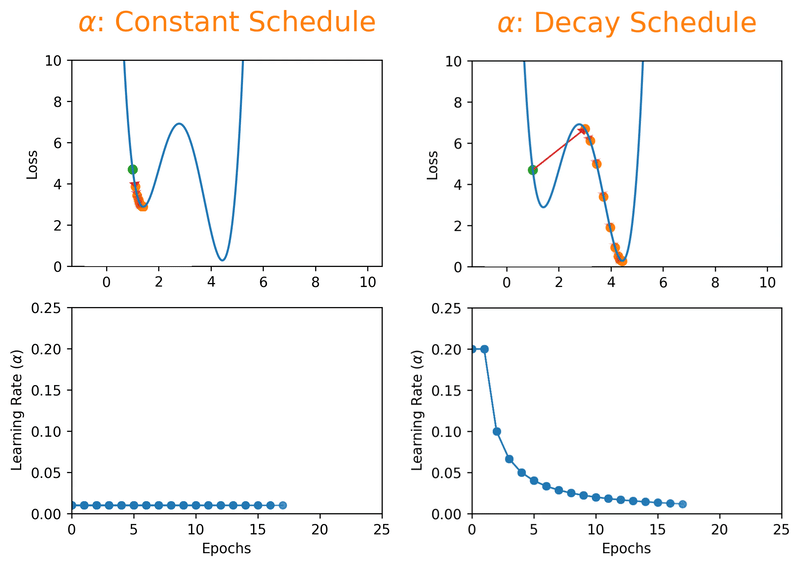
Momentum, Batch Size, and the Balancing Act
Momentum helps smooth things out by remembering which direction you've been heading, kind of like a ball rolling downhill that doesn't stop at every little dip [1]. Batch size is another interesting trade-off, smaller batches tend to generalize better because they add a bit of noise that helps escape local minima, though they're slower to train [2, 3]. And then there's the architecture itself: how many layers, how many nodes, how much regularization. Too simple and you underfit; too complex and you overfit. It's a balancing act.
The Search for Optimal Hyperparameters
When it comes to actually searching for the best hyperparameters, you've got options ranging from brute-force grid search to smarter approaches like Bayesian optimization, which learns from previous trials to focus on promising regions [4]. But since training is expensive, early stopping strategies like Successive Halving and HyperBand have become popular, they essentially give every configuration a quick audition and cut the underperformers early, saving your compute budget for the winners [5, 6].
The key takeaway? Start with a baseline, add complexity gradually, and let your validation metrics guide you. And maybe use one of the many toolkits out there, Ray Tune, Optuna, Keras-Tuner, so you're not reinventing the wheel [7, 8, 9].